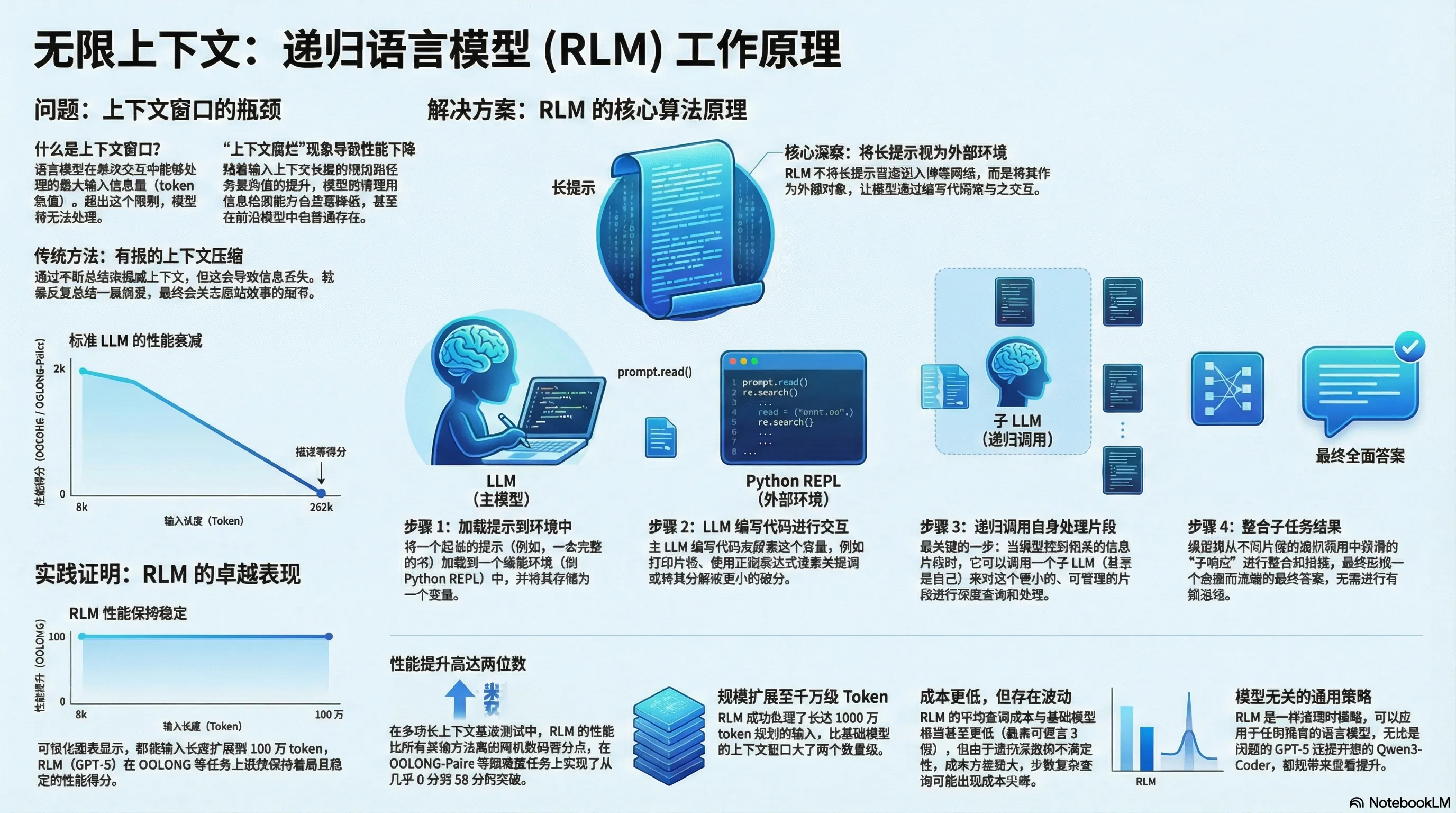
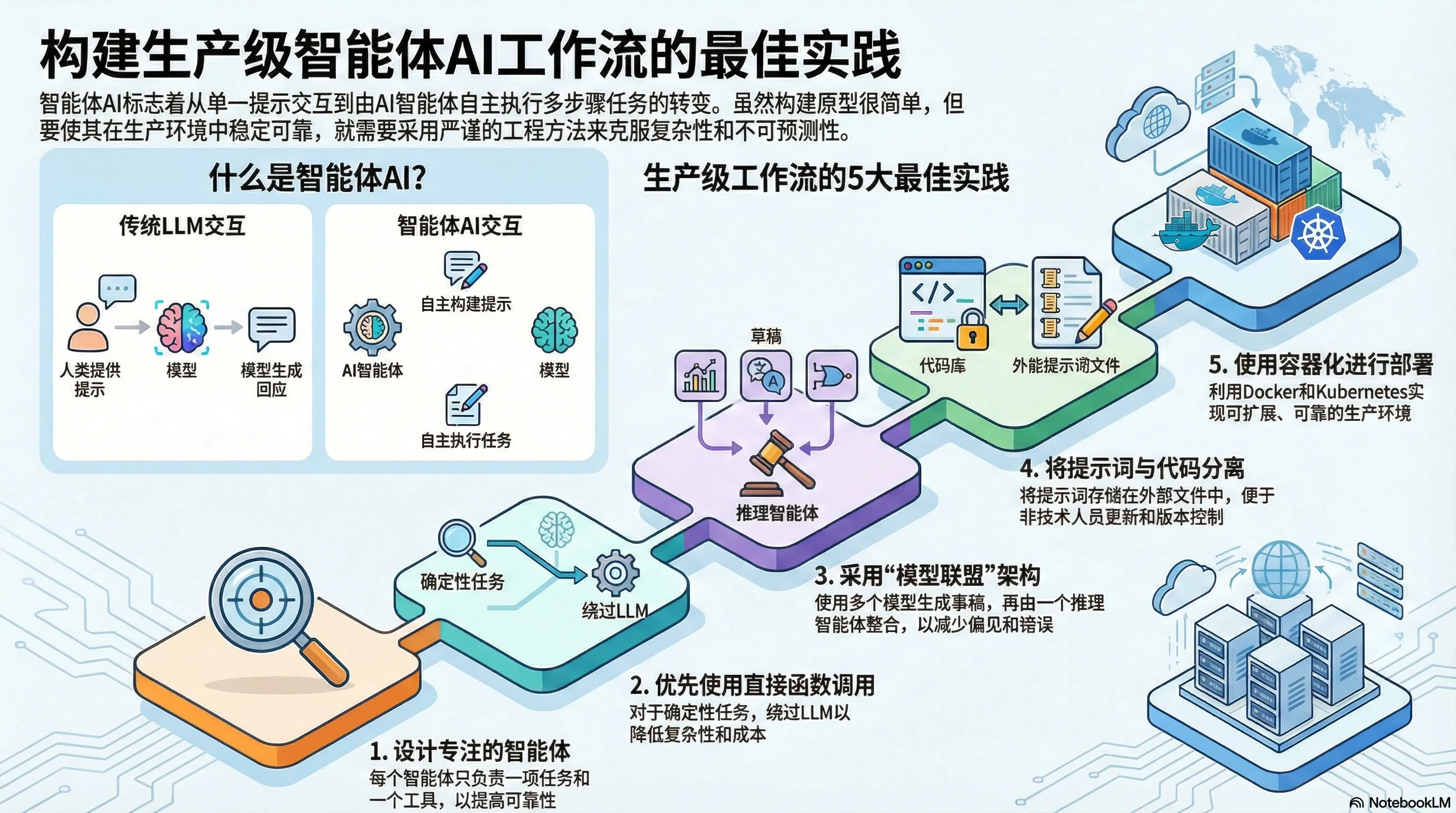
papers
计算受限观测者视角下的信息度量新范式 - 卡内基梅隆
论文探讨了人工智能领域中数据选择与泛化能力的关系,并提出了核心概念“Epiplexity”(外延复杂度)。作者指出,传统的信息论在面对计算受限的观察者时存在局限性,无法准确衡量数据中可被学习的结构化信息**。通过分析三个信息悖论,研究揭示了数据的排列顺序、计算约束以及涌现现象如何影响模型获取信息。实验证明,Epiplexity 能够比传统的交叉熵(Entropy)更有效地预测模型在分布外任务(OOD)上的表现。该理论为优化预训练数据选择提供了数学工具,强调了在资源有限的情况下,结构信息的提取是提升通用智能的关键。